
On Monday the 25th of January 2010 I visited the Australian Open [1] – it’s one of the world’s greatest tennis championships and it’s on in Melbourne right now. IBM sponsored my visit to show me the computer technology that they use to run the event and display the results to the world via their web site and to various media outlets.
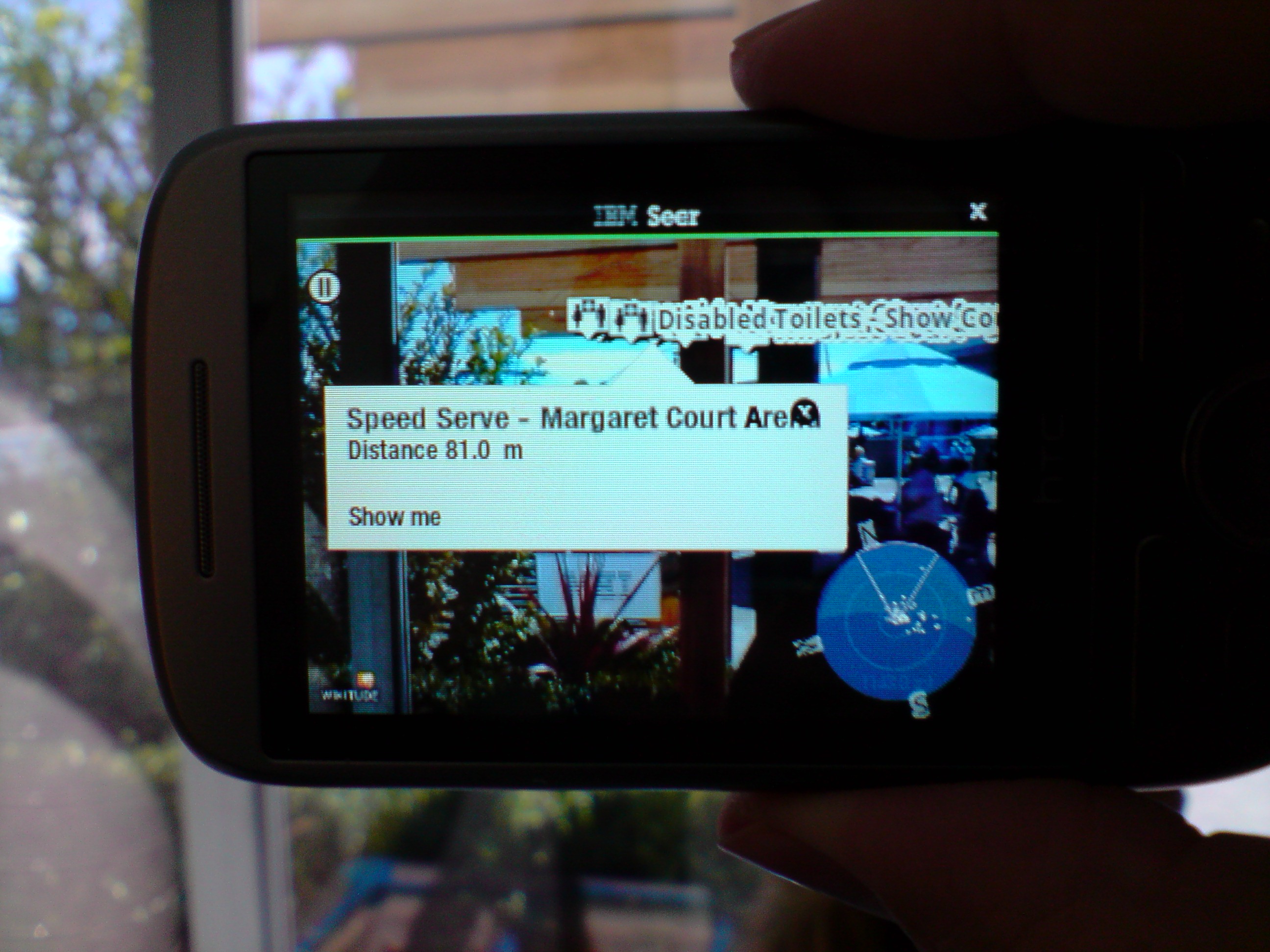
The first thing that they showed me was the IBM Seer software on the HTC Hero phone (which runs the Google Android OS). Seer can be freely downloaded from the Android store. The most noteworthy feature is that it uses the camera in the Android phone to display a picture of whatever you are looking at with points of interest superimposed (such as the above picture where I asked for locations of events and toilets). But it also displays a map view and has some other features I didn’t get a chance to test such as viewing twitter data relevant to the event. We really need this augmented reality feature enabled with tourist data for major cities. I’m sure that there’s lots of interesting things I haven’t seen in my own home city, if I could just pull out a phone and see a map of what’s around me whenever I’m bored I could see some of them. I think that this has the potential to change the way we use phones, in theory this was available as soon as Google Maps was released, but Seer seems to be the start of a whole new range of developments. One of the uses of this will be for identifying the background in tourist photos, no more of the “me in front of old building” descriptions.
Here is a Youtube Video of the Seer software in action [BMLgHGV4zWM].
The tour guide explained that to get the software to work on an iPhone would require the 3GS for navigation as the earlier iPhones don’t have a compass. The Seer software was initially developed for The Championships, Wimbledon 2009 which happened at about the same time as the iPhone 3GS release. I expect that there will be enough iPhone 3GS units sold before Wimbledon 2010 to give IBM a good incentive to port Seer to the iPhone.
Three (my phone company at the moment) has just sold out of the HTC Magic which has a digital compass. They are selling the HTC Touch Pro and HTC Touch Diamond that appear to lack a digital compass. Vodaphone is offering a HTC Magic free on the $29 contract right now. The other Australian mobile phone companies don’t seem to offer any Android phones. So it seems that the only option right now if I wanted to purchase a phone in Australia that can run Seer is the Vodaphone HTC Magic, and that’s a phone that was released almost a year ago (a long time with recent progress in phone development – it’s the modem before the HTC Hero I tested) and which has only a 3.2MP camera (the LG U990 Viewty I used to take the picture for this post has a 5MP camera and is older than that). So I expect that there aren’t many people using Seer in Australia.
If you happen to be in Melbourne and have an Android phone with a digital compass then you may want to visit the Australian open to try the Seer software. It should work equally well from outside the security fence…
I’ll write about the other things I saw over the next few days.


