As correctly pointed out by cmot [1] my previous post about software RAID [2] made no mention of bus bandwidth.
I have measured the bus bottlenecks of a couple of desktop machines running IDE disks with my ZCAV [3] benchmark (part of the Bonnie++ suite). The results show that two typical desktop machines had significant bottlenecks when running two disks for contiguous read operations [4]. Here is one of the graphs which shows that when two disks were active (on different IDE cables) the aggregate throughput was just under 80MB/s on a P4 1.5GHz while the disks were capable of delivering up to 120MB/s:
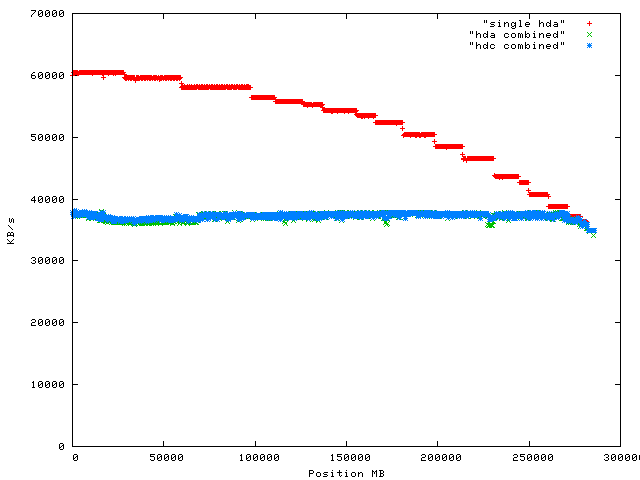
On a system such as the above P4 using software RAID will give a performance hit when compared to a hardware RAID device which is capable of driving both disks at full speed. I did not benchmark the relative speeds of read and write operations (writing is often slightly slower), but if for the sake of discussion we assume that read and write give the same performance then software RAID would only give 2/3 the performance of a theoretical perfect hardware RAID-1 implementation for large contiguous writes.
On a RAID-5 array the bandwidth for large contiguous writes is the data size multiplied by N/(N-1) (where N is the number of disks), and on a RAID-6 array it is N/(N-2). For the case of a four disk RAID-6 array that would give the same overhead as writing to a RAID-1 and for the case of a minimal RAID-5 array it would be 50% more writes. So from the perspective of “I need X bandwidth, can my hardware deliver it” if I needed 40MB/s of bandwidth for contiguous writes then a 3 disk RAID-5 might work but a RAID-1 definitely would hit a bottleneck.
Given that large contiguous writes to a RAID-1 is a corner case and that minimal sized RAID-5 and RAID-6 arrays are rare in most cases there should not be a significant overhead. As the number of seeks increases the actual amount of data transferred gets quite small. A few years ago I was running some mail servers which had a very intense IO load, four U320 SCSI disks in a hardware RAID-5 array was a system bottleneck – yet the IO was only 600KB/s of reads and 3MB/s of writes. In that case seeks were the bottleneck and write-back caching (which is another problem area for Linux software RAID) was necessary for good performance.
For the example of my P4 system, it is quite obvious that with a four disk software RAID array consisting of disks that are reasonably new (anything slightly newer than the machine) there would be some bottlenecks.
Another problem with Linux software RAID is that traditionally it has had to check the consistency of the entire RAID array in the case of an unexpected power failure. Such checks are the best way to get all disks in a RAID array fully utilised (Linux software RAID does not support reading from all disks in a mirror and checking that they are consistent for regular reads), so of course the issue of a bus bottleneck becomes an issue.
Of course the solution to these problems is to use a server for server tasks and then you will not run out of bus bandwidth so easily. In the days before PCI-X and PCIe there were people running Linux software RAID-0 across multiple 3ware hardware controllers to get better bandwidth. A good server will have multiple PCI buses so getting an aggregate throughput greater than PCI bus bandwidth is possible. Reports of 400MB/s transfer rates using two 64bit PCI buses (each limited to ~266MB/s) were not uncommon. Of course then you run into the same problem, but instead of being limited to the performance of IDE controllers on the motherboard in a desktop system (as in my test machine) you would be limited to the number of PCI buses and the speed of each bus.
If you were to install enough disks to even come close to the performance limits of PCIe then I expect that you would find that the CPU utilisation for the XOR operations is something that you want to off-load. But then on such a system you would probably want the other benefits of hardware RAID (dynamic growth, having one RAID that has a number of LUNs exported to different machines, redundant RAID controllers in the same RAID box, etc).
I think that probably 12 disks is about the practical limit of Linux software RAID due to these issues and the RAID check speed. But it should be noted that the vast majority of RAID installations have significantly less than 12 disks.
One thing that cmot mentioned was a RAID controller that runs on the system bus and takes data from other devices on that bus. Does anyone know of such a device?
Most recent desktop chipsets (for example S775 and AM2 platforms) have plenty of bandwidth and even decent onboard controllers most of the time. The Intel-based “media center” class motherboard I bought 6 months ago had no problems pulling 750MB/s out of the drives, only limited by the number of spindles I could fit in the case. This was using the onboard controller and a few cheap two-port silicon image PCI-E controllers. Linux SW raid of course slows this down a bit, but for other reasons than bus bandwidth.
You might want to look into updating zcav to deal with higher speed devices.. For example, here’s /dev/sda on an older hardware 14x300gig raid10 on a 3ware 9550SX-16, which does about 400M/s reads, and did over 600’s when it was configured as a 15×300 raid5. The bonnie++ is from Debian Etch on this sytem.
#loops: 1, version: 1.03
#block K/s time
#0 ++++ 0.319699
#100 ++++ 0.239653
#200 ++++ 0.238755
#300 ++++ 0.238268
#400 ++++ 0.238702
#500 ++++ 0.238440
#600 ++++ 0.239219
Oh, I almost forgot, “RAID controller that runs on the system bus and takes data from other devices on that bus” is usually branded as “Zero-Channel RAID” by the server vendors. They come in various forms, but most of them use the PCI bus to drive the onboard controllers which means increased bus utilization but keeps the XOR operations offloaded off the CPU and provides traditional raid management.
Mike: The “-b” option to zcav allows using larger block sizes which therefore take more time (and are regarded as more reliable by zcav). For your example “-b300” should do the job. I might increase the default block size for the next version.
Andre: Thanks for the information.
Zero Channel RAID:
Two products, as examples:
http://www.lsi.com/storage_home/products_home/internal_raid/megaraid_scsi/megaraid_scsi_3200/index.html
http://www.adaptec.com/en-US/products/raid_tech/scsi_drives/ASR-2020ZCR/
Adaptec whitepaper:
http://www.virtual.com/whitepapers/Adaptec_An_Analysis_Of_PCI_wp.pdf
which provides some calculated numbers.